
Smarter, Faster Information Retrieval: How AI-Powered RAG and CAG Can Streamline Your Business Tasks
Case Studies Smarter, Faster Information Retrieval: How AI-Powered RAG and CAG Can Streamline Your Business Tasks Adam Sinnott 28...
Adam Sinnott
28 May, 2025
AI is transforming our world. It’s driving lots of big technological changes, but how would it affect the little things, like researching some local history, finding out when your next Parish Council meeting is taking place or when your next bin collection might be.
You’re in a meeting and someone mentions an aspect of a project that was minuted a few months ago. There’s a discussion about what was agreed and you want to check the minutes to see if it matched what you remembered. Get the answer in seconds instead of trawling through pages of old minutes.
Want to know how to disassemble and diagnose some faulty machinery but you are not sure where to look in the technical manuals?
Even if it’s proprietary tech, just load in your manuals and an AI can give you step by step instructions augmented by its own knowledge.
For this demonstration, we partnered with Friends of Droxford Church who hold a number historical documents on their website that we could feed in to our database. Droxford also has a good online presence for local government and other resources that will add additional value for villagers.
Adding these documents in to a database for retrieval by an AI or LLM (Large Language Model), is called either RAG (Retrieval Augmented Generation) or CAG (Cache Augmented Generation).
In RAG, you break your documents down in to small typically 1000 character chunks and use an AI to store them in a database. Using an AI to store them allows for much greater recall of information over normal database recalls, it’s cost-effective as you only get your information in 1000 character chunks, making AI use cheaper (they charge per token which is roughly equal to a character). With a users query an AI LLM can then attempt to build the correct query to return the relevant documents.
In CAG, we pass all of the documents to an AI LLM, along with the the users query. This was not possible until recently when the context window (how many characters an AI LLM can handle before getting confused and shutting down) was large enough to handle lots of text. LLMs like OpenAI’s gpt-4.1-mini and Google’s gemini-2.0-flash can now get up to ~1,000,000 characters or ~2 standard novels (~100,000 words each).
In this project we investigated two solutions:
RAG & CAG
We elected to use n8n for this example, a popular workflow automation tool, it provides a simple easy to use interface, it hosts our solutions for a reasonable price and has many integrations right out of the box like connecting to Google Drive or sending emails etc without having to reinvent the wheel.
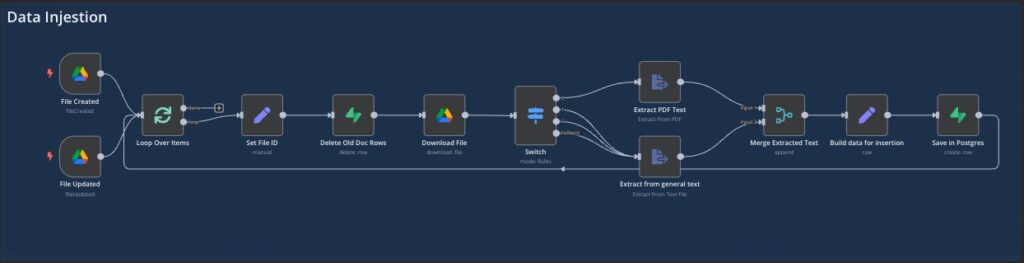
RAG was the initial AI workflow implemented using n8n. Documents were uploaded to Google Drive, where n8n monitored for new additions, broke these documents into manageable chunks, and stored them in a Supabase vector database.
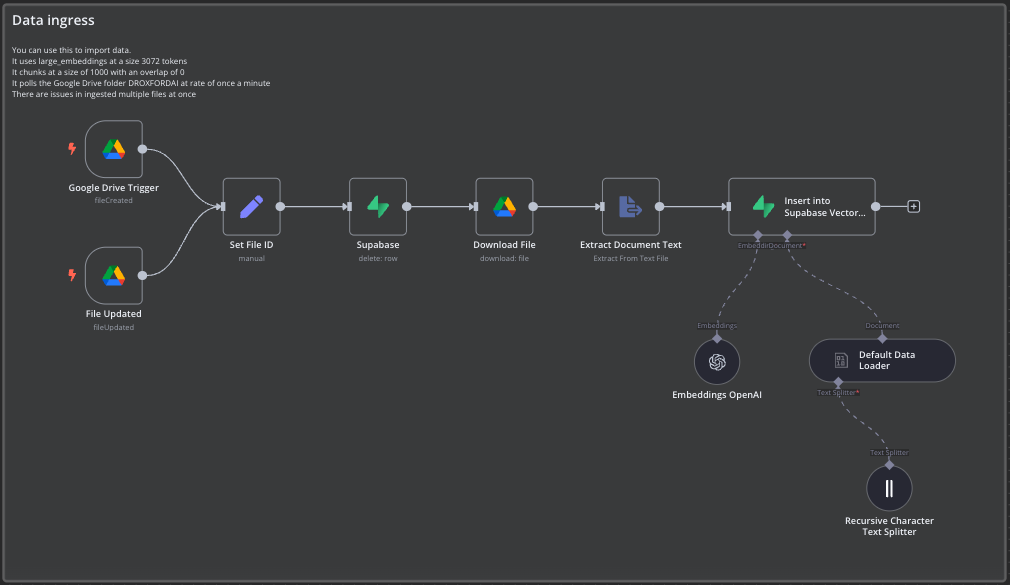
Queries submitted via a chat app triggered n8n to retrieve relevant document chunks, passing these along with user queries to an AI chat model.
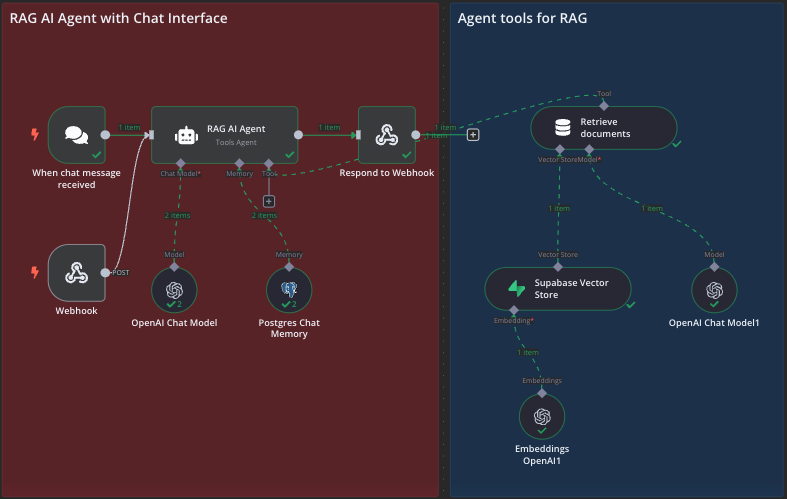
To address the inherent accuracy issues of RAG, the project experimented with a CAG setup. Instead of breaking documents into chunks, each document was stored entirely in a PostgreSQL database.
Queries retrieved the full documents, combined them into one variable via a code node, and then presented them to the AI model along with a memory component.
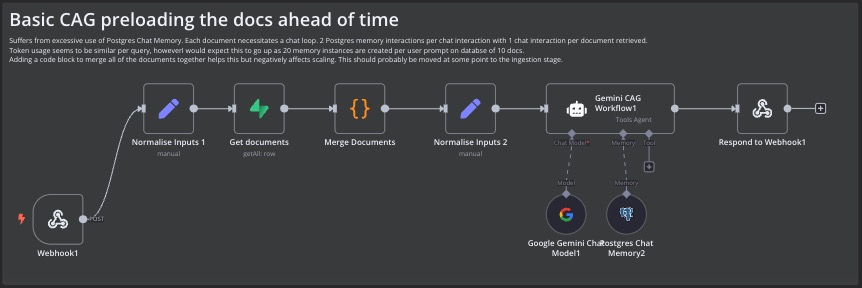
Initially we used the n8n AI Agent’s tool database attachment to retrieve all of the documents, but occasionally the Gemini model wouldn’t search the database and answer saying it had no information. It was quite a strange moment, trying to convince a computer to look in the database for the documents. Certainly highlights what future issues with an AI could bring. In the end we just passed all of the documents along with the users query and gave it no choice but to look at them. Open AI models didn’t have any issue with this.
Key benefits of CAG:
However, this came with its own trade-offs:
The project team tested multiple AI models including OpenAI’s GPT-4.1-mini and Google’s Gemini 2.0-flash.
OpenAI GPT-4.1-mini:
Gemini 2.0-flash:
| Model | Input Price (per 1M tokens) | Output Price (per 1M tokens) |
|---|---|---|
| gemini-2.0-flash | $0.10 | $0.40 |
| gpt-4.1-mini | $0.40 | $1.60 |
As regards to accuracy, queries about historical figures such as John De Drokensford yielded noticeably more detailed and coherent results from OpenAI’s models compared to Gemini.
Ultimately, the Droxford AI project found that CAG delivered superior accuracy, making it highly suitable for applications where precise recall outweighs cost considerations. RAG, on the other hand, offered an economical alternative suitable for less context-sensitive applications.
For SMBs evaluating AI retrieval methods, a hybrid CAG-RAG approach could provide an optimal balance—offering high accuracy at manageable costs. Summarising documents before retrieval could significantly reduce token use, mitigating cost concerns.
By understanding the strengths and limitations of both RAG and CAG, businesses can harness AI effectively to enhance customer interactions and streamline knowledge delivery, providing genuine value without breaking the bank.
Case Studies Smarter, Faster Information Retrieval: How AI-Powered RAG and CAG Can Streamline Your Business Tasks Adam Sinnott 28...

Latest Developments React Native’s latest update 0.76 Adam Sinnott 7 November, 2024 React Native is a continuously evolving and...

Productivity How React Native Can Shorten Development Time Adam Sinnott 31 July, 2024 React Native, a popular framework developed...

Uncategorized The Impact of Labour Productivity on Business Growth in the UK July 30, 2024 One of the main...
Droxford, Meon Valley, Hampshire
info@appcreators.co.uk
(+44) 01489 287009
Building trust and apps to unlock your productivity.
AppCreators. All rights reserved.